Reading List
The most recent articles from a list of feeds I subscribe to.
Resolve Promises externally with this one weird trick
Those of us who use promises heavily, have often wished there was a Promise.prototype.resolve() method, that would force an existing Promise to resolve. However, for architectural reasons (throw safety), there is no such thing and probably never will be. Therefore, a Promise can only resolve or reject by calling the respective methods in its constructor:
var promise = new Promise((resolve, reject) => {
if (something) {
resolve();
}
else {
reject();
}
});
However, often it is not desirable to put your entire code inside a Promise constructor so you could resolve or reject it at any point. In my latest case today, I wanted a Promise that resolved when a tree was created, so that third-party components could defer code execution until the tree was ready. However, given that plugins could be running on any hook, that meant wrapping a ton of code with the Promise constructor, which was obviously a no-go. I had come across this problem before and usually gave up and created a Promise around all the necessary code. However, this time my aversion to what this would produce got me to think even harder. What could I do to call resolve() asynchronously from outside the Promise?
A custom event? Nah, too slow for my purposes, why involve the DOM when it’s not needed?
Another Promise? Nah, that just transfers the problem.
An setInterval to repeatedly check if the tree is created? OMG, I can’t believe you just thought that Lea, ewwww, gross!
Getters and setters? Hmmm, maybe that could work! If the setter is inside the Promise constructor, then I can resolve the Promise by just setting a property!
My first iteration looked like this:
this.treeBuilt = new Promise((resolve, reject) => {
Object.defineProperty(this, "_treeBuilt", {
set: value => {
if (value) {
resolve();
}
}
});
});
// Many, many lines below…
this._treeBuilt = true;
However, it really bothered me that I had to define 2 properties when I only needed one. I could of course do some cleanup and delete them after the promise is resolved, but the fact that at some point in time these useless properties existed will still haunt me, and I’m sure the more OCD-prone of you know exactly what I mean. Can I do it with just one property? Turns out I can!
The main idea is realizing that the getter and the setter could be doing completely unrelated tasks. In this case, setting the property would resolve the promise and reading its value would return the promise:
var setter;
var promise = new Promise((resolve, reject) => {
setter = value => {
if (value) {
resolve();
}
};
});
Object.defineProperty(this, "treeBuilt", {
set: setter,
get: () => promise
});
// Many, many lines below…
this.treeBuilt = true;
For better performance, once the promise is resolved you could even delete the dynamic property and replace it with a normal property that just points to the promise, but be careful because in that case, any future attempts to resolve the promise by setting the property will make you lose your reference to it!
I still think the code looks a bit ugly, so if you can think a more elegant solution, I’m all ears (well, eyes really)!
Update: Joseph Silber gave an interesting solution on twitter:
function defer() {
var deferred = {
promise: null,
resolve: null,
reject: null
};
deferred.promise = new Promise((resolve, reject) => {
deferred.resolve = resolve;
deferred.reject = reject;
});
return deferred;
}
this.treeBuilt = defer();
// Many, many lines below…
this.treeBuilt.resolve();
I love that this is reusable, and calling resolve() makes a lot more sense than setting something to true. However, I didn’t like that it involved a separate object (deferred) and that people using the treeBuilt property would not be able to call .then() directly on it, so I simplified it a bit to only use one Promise object:
function defer() {
var res, rej;
var promise = new Promise((resolve, reject) => {
res = resolve;
rej = reject;
});
promise.resolve = res;
promise.reject = rej;
return promise;
}
this.treeBuilt = defer();
// Many, many lines below…
this.treeBuilt.resolve();
Finally, something I like!
URL rewriting with Github Pages
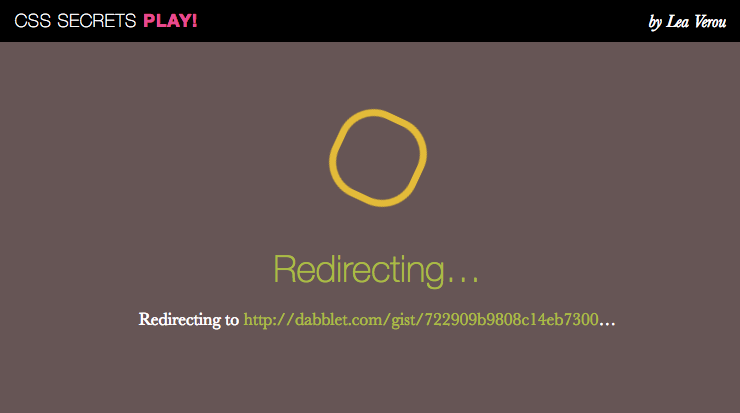 I adore Github Pages. I use them for everything I can, and try to avoid server-side code like the plague, exactly so that I can use them. The convenience of pushing to a repo and having the changes immediately reflected on the website with no commit hooks or any additional setup, is awesome. The free price tag is even more awesome. So, when the time came to publish my book, naturally, I wanted the companion website to be on Github Pages.
I adore Github Pages. I use them for everything I can, and try to avoid server-side code like the plague, exactly so that I can use them. The convenience of pushing to a repo and having the changes immediately reflected on the website with no commit hooks or any additional setup, is awesome. The free price tag is even more awesome. So, when the time came to publish my book, naturally, I wanted the companion website to be on Github Pages.
There was only one small problem: I wanted nice URLs, like http://play.csssecrets.io/pie-animated, which would redirect to demos on dabblet.com. Any sane person would have likely bitten the bullet and used some kind of server-side language. However, I’m not a particularly sane person :D
Turns out Github uses some URL rewriting of its own on Github Pages: If you provide a 404.html, any URL that doesn’t exist will be handled by that. Wait a second, is that basically how we do nice URLs on the server anyway? We can do the same in Github Pages, by just running JS inside 404.html!
So, I created a JSON file with all demo ids and their dabblet URLs, a 404.html that shows either a redirection or an error (JS decides which one) and a tiny bit of Vanilla JS that reads the current URL, fetches the JSON file, and redirects to the right dabblet. Here it is, without the helpers:
(function(){
document.body.className = 'redirecting';
var slug = location.pathname.slice(1);
xhr({
src: 'secrets.json',
onsuccess: function () {
var slugs = JSON.parse(this.responseText);
var hash = slugs[slug];
if (hash) {
// Redirect
var url = hash.indexOf('http') == 0? hash : 'https://dabblet.com/gist/' + hash;
$('section.redirecting > p').innerHTML = 'Redirecting to <a href="' + url + '">' + url + '</a>…';
location.href = url;
}
else {
document.body.className = 'error not-found';
}
},
onerror: function () {
document.body.className = 'error json';
}
});
})();
That’s all! You can imagine using the same trick to redirect to other HTML pages in the same Github Pages site, have proper URLs for a single page site, and all sorts of things! Is it a hack? Of course. But when did that ever stop us? :D
URL rewriting with Github Pages
I adore Github Pages. I use them for everything I can, and try to avoid server-side code like the plague, exactly so that I can use them. The convenience of pushing to a repo and having the changes immediately reflected on the website with no commit hooks or any additional setup, is awesome. The free price tag is even more awesome. So, when the time came to publish my book, naturally, I wanted the companion website to be on Github Pages.
There was only one small problem: I wanted nice URLs, like http://play.csssecrets.io/pie-animated, which would redirect to demos on dabblet.com. Any sane person would have likely bitten the bullet and used some kind of server-side language. However, I’m not a particularly sane person :D
Turns out Github uses some URL rewriting of its own on Github Pages: If you provide a 404.html, any URL that doesn’t exist will be handled by that. Wait a second, is that basically how we do nice URLs on the server anyway? We can do the same in Github Pages, by just running JS inside 404.html!
So, I created a JSON file with all demo ids and their dabblet URLs, a 404.html that shows either a redirection or an error (JS decides which one) and a tiny bit of Vanilla JS that reads the current URL, fetches the JSON file, and redirects to the right dabblet. Here it is, without the helpers:
(function(){
document.body.className = 'redirecting';
var slug = location.pathname.slice(1);
xhr({
src: 'secrets.json',
onsuccess: function () {
var slugs = JSON.parse(this.responseText);
var hash = slugs[slug];
if (hash) {
// Redirect
var url = hash.indexOf('http') == 0? hash : 'http://dabblet.com/gist/' + hash;
$('section.redirecting > p').innerHTML = 'Redirecting to <a href="' + url + '">' + url + '</a>…';
location.href = url;
}
else {
document.body.className = 'error not-found';
}
},
onerror: function () {
document.body.className = 'error json';
}
});
})();
That’s all! You can imagine using the same trick to redirect to other HTML pages in the same Github Pages site, have proper URLs for a single page site, and all sorts of things! Is it a hack? Of course. But when did that ever stop us? :D
Autoprefixing, with CSS variables!
Recently, when I was making the minisite for markapp.io, I realized a neat trick one can do with CSS variables, precisely due to their dynamic nature. Let’s say you want to use a property that has multiple versions: an unprefixed one and one or more prefixed ones. In this example we are going to use clip-path, which currently needs both an unprefixed version and a -webkit- prefixed one, however the technique works for any property and any number of prefixes or different property names, as long as the value is the same across all variations of the property name.
The first part is to define a --clip-path property on every element with a value of initial. This prevents the property from being inherited every time it’s used, and since the * has zero specificity, any declaration that uses --clip-path can override it. Then you define all variations of the property name with var(--clip-path) as their value:
* {
--clip-path: initial;
-webkit-clip-path: var(--clip-path);
clip-path: var(--clip-path);
}
Then, every time we need clip-path, we use --clip-path instead and it just works:
header {
--clip-path: polygon(0% 0%, 100% 0%, 100% calc(100% - 2.5em), 0% 100%);
}
Even !important should work, because it affects the cascading of CSS variables. Furthermore, if for some reason you want to explicitly set -webkit-clip-path, you can do that too, again because * has zero specificity. The main downside to this is that it limits browser support to the intersection of the support for the feature you are using and support for CSS Variables. However, all browsers except Edge support CSS variables, and Edge is working on it. I can’t see any other downsides to it (except having to use a different property name obvs), but if you do, let me know in the comments!
I think there’s still a lot to be discovered about cool uses of CSS variables. I wonder if there exists a variation of this technique to produce custom longhands, e.g. breaking box-shadow into --box-shadow-x, --box-shadow-y etc, but I can’t think of anything yet. Can you? ;)
Autoprefixing, with CSS variables!
Recently, when I was making the minisite for markapp.io, I realized a neat trick one can do with CSS variables, precisely due to their dynamic nature. Let’s say you want to use a property that has multiple versions: an unprefixed one and one or more prefixed ones. In this example we are going to use clip-path, which currently needs both an unprefixed version and a -webkit- prefixed one, however the technique works for any property and any number of prefixes or different property names, as long as the value is the same across all variations of the property name.
The first part is to define a --clip-path property on every element with a value of initial. This prevents the property from being inherited every time it’s used, and since the * has zero specificity, any declaration that uses --clip-path can override it. Then you define all variations of the property name with var(--clip-path) as their value:
* {
--clip-path: initial;
-webkit-clip-path: var(--clip-path);
clip-path: var(--clip-path);
}
Then, every time we need clip-path, we use --clip-path instead and it just works:
header {
--clip-path: polygon(0% 0%, 100% 0%, 100% calc(100% - 2.5em), 0% 100%);
}
Even !important should work, because it affects the cascading of CSS variables. Furthermore, if for some reason you want to explicitly set -webkit-clip-path, you can do that too, again because * has zero specificity. The main downside to this is that it limits browser support to the intersection of the support for the feature you are using and support for CSS Variables. However, all browsers except Edge support CSS variables, and Edge is working on it. I can’t see any other downsides to it (except having to use a different property name obvs), but if you do, let me know in the comments!
I think there’s still a lot to be discovered about cool uses of CSS variables. I wonder if there exists a variation of this technique to produce custom longhands, e.g. breaking box-shadow into --box-shadow-x, --box-shadow-y etc, but I can’t think of anything yet. Can you? ;)