Reading List
The most recent articles from a list of feeds I subscribe to.
Smart Phone, Dumb Terminal
I'm typing this post on my iPhone in the Obsidian iOS app using a Logitech K380 Bluetooth keyboard and I feel like a 90s computer hacker.
Not enough? How about this: I just SSH'ed into a Raspberry Pi on my home network using Tailscale via the Termius iOS app to restart a YouTube-playlist-to-podcast-feed Docker container.
Don't get me wrong -- the other stuff is pretty magical, too, especially Tailscale. But this keyboard-to-phone takes the cake.
I mean, look at this:

It's downright cute, aside from the legs.
You kinda forget that your phone is a computer, personally-speaking. Instead, it's usually just a vehicle for social media nightmares. Given the choice between doing something semi-arduous, like checking in for a flight, on a phone app vs the website (on a desktop/laptop), I always choose the latter. Somethings always missing from the app, and if you really want to get all fiddly, which I usually do, they kick you out to a crappy webview anyway.
So, I'm usually a laptop-bringer on any trip. Except, this time, I didn't want to. Firstly, my alu-min-i-um portable computer is just plain heavy and bulky, and I was adamant that we were going carry-on only on this voyage. Even more damning, I recently discovered that opening the laptop screen beyond 45 degrees results in the black screen of death. That's something for the Geniuses, if they're willing indulge an admittedly long in the tooth 2016 MBP (I'm doubtful).
But I did want to be able to work on edits for my book on this trip. You never know when inspirations gonna strike (usually, for me, around midnight, when I've already gone to bed), and while I'm reasonably fast thumb-typist, I just don't feel the flow feels on the phone keyboard.
Luckily, we had this little Bluetooth cutie tucked away in a closet. I'd purchased it as a gift for Carly, so that she could write stuff on the go (very much the same need I'm talking about here). We'd extensively discussed the need for a mobile keyboard writing thingie early in our courtship, and we even entertained the idea of building it ourselves (hint: I'm still entertaining this idea).
We're not alone. See the FreeWrite products, which somehow don't quite fit the bill for me, despite almost exactly delivering on our dream product (full-sized keyboard, e-ink-like screen, and supreme battery life). Mostly it's the calculator-sized screen (and the perceived bulky size) that's scaring me away. We want something that you can keep in a purse or a pocket.
Now this Bluetooth keyboard doesn't fit in a pocket, but it's also pretty darn cheap, enough so that I'm not going to be devastated if I lose it or spill a beer on it.
So, I thought I'd give it a try this trip. And I'm sold. It's legit fun to type on this thing and I think I'm going to bring it with me more places. Along with things like Tailscale and Termius, I can treat my smart phone as a dumb terminal to my real computers.
Carly still hasn't given the keyboard a try, but I'm holding out hope. She's watching me tap-tap away right now, and I think this is a gift that just takes a while to kick in.
And, meanwhile, I'm going to keep thinking about keyboards-as-computers, whether that's scouring eBay for Commodore VIC-20s, ogling over the latest Raspberry Pi 400 keyboard-computer, or sketching out our still-yet-to-be-realized "Kindle for writing."
On the latter item, I'm also ogling the ReMarkable 2 as an potential winning entrant, but the lack of keyboard and the lack of backlight are keeping me away... for now. If they're tracking dropped cart analytics at all, I'm just going to apologize now for what I've been doing. You can keep retargeting me if you'd like. You'll get me one day.
Writes With
Earlier today, I texted some friends that I regret using Gatsby for this blog. It came at a moment of frustration, when I was stuck in some weird Node dependencies hell and all I wanted was to write another blog post.
If your static site generator does nothing else, it should make it frictionless to write a new blog post. It's hard enough to make the time to write, your software shouldn't be making it harder.
Why did I use Gatsby in the first place? Well, it was new and shiny and uses GraphQL. That's enough, right? Really, at the time, I had these grand ambitions of interactive React components within my posts, which I knew would be possible, and possibly easy, with a React-based static site generator. To this date, I've written exactly one of these interactive posts, and that was before I made the Gatsby-switch and I still have never actually ported it from my original Pelicon static site. This post used to have all these Tie Fighters flying around and now it doesn't and I'm still a little bummed about it. If any of that intrigues you, my little Star Wars game is still online - it's one of the first things I ever made when I learned how to program.
So, anyway, why not switch away from Gatsby? Am I using any of the advanced features of Gatsby? Yes, I am. There's an active plugin ecosystem and I use a bunch of them for things like generating my RSS feed or rendering images or displaying my library or my Instagram posts. But I've realized that some of these, especially the ones that leverage external APIs like the Instagram one, are more trouble than they're worth.
With the Instagram plugin/API, all I want to do is display a neat little grid of all the "walking man" street signs I've discovered and posted to Instagram. But, like all Web 2.0 API platforms, Instagram's API usefulness was continually walked back until it's virtually impossible to do basic things like display your photos (because they want to keep all these useful actions within their own platform/app), and I'm now forced to create a "test account" on a Facebook "app" with a temporary token that expires like every 30 days or something. Now, every time I go to write a new post here, which is usually > 30 days, I can't even build my blog locally because the Gatsby build process fails from the expired Instagram token. I want to blame Instagram here, or Gatsby, but instead, I blame myself.
Keep your friends close, and your blog's dependencies closer.
A simpler static site generator
Here's where I announce that I've written a new, better, static site generator, the fourth step in the hero's journey of software engineering.
But, nope. Instead, I'm just gonna use the one that my pal Ben created. It's called Syte. It's extremely lightweight, fast, and does exactly what I really want -- render Markdown files in an HTML template.
So, have I switched my blog over to Syte yet? Not yet. But I'm gonna. The main thing that's missing (for me) in Syte is RSS feed generation. I'd like to contribute that back to Ben's repo at some point. I can probably live without the rest of the junk I've bolted onto this site. It may mean that I temporarily dismantle my cool, query-param powered library searching page, but that's a worthy price to pay for being able to write a blog post exactly when I want to, no questions asked.
My inability to bear the blog switching costs at this moment isn't going to stop me from another time-waster of a side project: a new interview site, using Syte, that asks writers about the stuff they use to write, edit, and otherwise create their books!
Writes With

The Writes With syte is already live, with two interviews: Brian Dear, author of The Friendly Orange Glow: The Untold Story of the PLATO System and the Dawn of Cyberculture, and Pooja Reddy, author of The Big Bold Blue.
Making it was a joy with Syte and I'm happy with it, even if my "design" is still pretty bare bones. I also deployed it with Cloudflare Pages, which mostly importantly comes with (at least for now) free bandwidth. This blog uses Netlify for hosting, which I do like, but occasionally suffer from bandwidth spikes near the end of the monthly billing cycles that trigger their bandwidth "add-ons" fees.
Writes With is directly, clearly, obviously, duh inspired by one of my favorite websites: usesthis.com. In fact, I chatted with Daniel of usesthis.com before launching it, just to make sure he was okay with it, and he gave the thumbs up.
I like this little project, because I'm going to get to talk with more people who've published books. As a cub writer myself, I'm happy for any tips and tricks I can get.
And I know, I know, the tools aren't the important thing about writing... but I think we all still want to know about them.
Computers by the Decade
I've been doing a lot of research into the history of computers1 for my forthcoming Middle Grade novel about robots (as of March 2021, I'm linking to a largely blank page here, which I assure you will one day be filled with the multitude of books I'm going to write - end Daily Affirmation now).
I'd like to share my current, wait for it, mental model for how I'm thinking about the evolution of computing over the decades. I'll also highlight some current companies that I find interesting because they seem to be fellow computer historians.
First, a caveat canem: 🐶 Since this website is my little corner of the dub-dub-dub, I reserve the right to update this framework as I learn more. And I will be learning more, because I can't stop reading about this stuff. I love it. So, there, take that, fellow computer historians! Even better, please let me know what I've messed up or got wrong so I can learn. Woof!
So, here's how I see the evolution of computers over the decades (including some predictions):
| Decade | Computers |
|---|---|
| 1940s | Analog |
| 1950s | Digital |
| 1960s | Warehouse |
| 1970s | Mini |
| 1980s | 8-Bit PC |
| 1990s | Pentium PC |
| 2000s | Laptop |
| 2010s | Smart Phones |
| 2020s | Wearables |
| 2030s | Embeddables |
Lemme recap these a bit (in a freewheeling manner). We see the first "stored-program" digital computers coming to life in the late 40s. These are your o.g. "Von Neumann" architecture machines, the real-world implementations of the universal Turing machine vision from 1936. Goodbye, Vannevar Bush's Differential Analyzer -- we've now got computers that we can "re-wire" themselves with "code" instead of electromechanical widgets and whatnot that had to be manually reconfigured for different problems (usually military applications around this time, like calculating missile trajectories).
Then comes the era of the ominious Warehouse computer, dominated by Big Blue (IBM) and the angry BUNCH (Burroughs, UNIVAC, NCR, Control Data Corporation, and Honeywell) -- aka the FAANG of days of computer future past. Computers were huge, literally, during the 60s and 70s. Actual insects would get lodged inside them and wreak havoc -- "bugs"! This was also around the time that people thought there might only need to be a handful of computers in the whole wide world -- that computers would be a public utility like telephone service.
Along related lines, this is where folks started experimenting with "computer networking." Let's layer that strand into our decades framework:
| Decade | Computers | Networking |
|---|---|---|
| 1940s | Analog | N/A |
| 1950s | Digital | N/A |
| 1960s | Warehouse | Timeshare |
| 1970s | Mini | ARPANET |
| 1980s | 8-Bit PC | Internet |
| 1990s | Pentium PC | WWW |
| 2000s | Laptop | Web 2.0 |
| 2010s | Smart Phones | Apps |
| 2020s | Wearables | TBD |
| 2030s | Embeddables | TBD |
Timesharing. You've probably heard of it before. Essentially, the few people lucky enough to have access to these machines would sit at "dumb" Teletype terminals and their commands would be executed in some mainframe somewhere else (usually their university). You didn't have to own a computer to use one, you just needed to pay for access (sounds a lot like "cloud computing" nowadays, right? Time is a flat circle). It wasn't just all university-work. Games were being created and shared, and projects like PLATO at University of Illinois were doing interactive things that seem impossible for their era:
Take a look at the rows for 80s and 90s - you're basically looking at Halt and Catch Fire season by season.2 Personal computers. The World Wide Web. AOL Instant Messager. This is where things start hitting hard on the nostalgia receptors for me. I'll never forget the early `90s Christmas where we got our SoundBlaster 16 sound card. Carmen Sandiego never sounded so good.
Let's fast-forward to the new millenium. Frankly, I'm increasingly less interested in the more recent eras of apps and smart phones. Even my predictions are boring to me. I don't have an Apple Watch. I know "AR" is coming (see recent WWDC teaser). I know we're going to be able to read brainwaves of pigs soon (or already are). I should probably keep more of an open mind about these upcoming technologies, so I'll try. But the history major in me just wants to go back and play with my Apple IIe.
When I think about it, there's tons of additional "strands" that could and should be tracked in this framework. For example, the evolution of memory type and memory capacity over time is super fascinating, and probably is the number one driver of the changes in the "computers" column.
Or another idea, even closer to my heart, would be adding the "definitive" book that should be read for each era. Actually, let me try that one.
| Decade | Computers | Networking | Book |
|---|---|---|---|
| 1940s | Analog | N/A | |
| 1950s | Digital | N/A | Turing's Cathedral |
| 1960s | Warehouse | Timeshare | The Friendly Orange Glow |
| 1970s | Mini | ARPANET | The Soul of a New Machine |
| 1980s | 8-Bit PC | Internet | Return to the Little Kingdom |
| 1990s | Pentium PC | WWW | Hard Drive |
| 2000s | Laptop | Web 2.0 | |
| 2010s | Smart Phones | Apps | |
| 2020s | Wearables | TBD | |
| 2030s | Embeddables | TBD |
I need some suggestions for the more recent eras!
Three Companies That Seem to Also Appreciate Computer History
Okay, onto the best part...
Replit
Replit is a company that makes it easy to spin up an IDE in any language, right in your browser. Goodbye painful local dev environment setup. Students LOVE it. Teachers LOVE it. School administrators apparently DON'T LOVE it (according to what I've seen on Twitter).
So, what does Replit know about computer history?
They are the modern timesharing system - global, instant access to compute, with collaboration as first-class objective. It's a place to learn, play games, write your own games, build apps, ship stuff. They're even talking about building their own hardware "dumb" terminal that connects instantly to Replit.
We're prototyping a computer that boots to Replit and is hardwired with a VPN to make it impossible to block.
— Amjad Masad ⠕ (@amasad) March 20, 2021
If it works, it will be free for students. Devs will pay full price with each computer sold will sponsor a student. https://t.co/8cQdhJqvFv pic.twitter.com/Qu1eTYYa1x
Timesharing is back. And this time you don't have to share, unless you want to!
Tailscale
Tailscale is a company that makes it dead simple to set up a VPN for all your devices: phones, Raspberry Pis, laptops, desktops, you name it.
So, what does Tailscale know about computer history?
They are making the 90s-LAN party possible again. It was a beautiful thing when you could "easily" make your computers talk to each other, but then the Internet got scary and hard, and Tailscale makes it safe and easy again.
I recently used Tailscale to set up a little Raspberry Pi-powered robot car. I can SSH into my little robot and drive it around, and I'm feeling like a kid again.

Oxide Computer Company
Oxide Computer Company is a new computer company. Like hardware-hardware computer company! They're building servers for folks who don't want to (or can't) just use AWS, GCP, Azure, Digital Ocean, blah blah... the cloud.
So, what does Oxide know about computer history?
More than me! Just listen to their epic podcast On the Metal to hear for yourself. They even went through a fun design project of redesigning their logo to look like definitive computer companies of days past..
But most importantly I think that Oxide harkens back to the `90s era of owning your compute infra end-to-end. We do not have to accept that everything will be in the cloud. Maybe your closet is a better choice. Tradeoffs, amiright? There are going to be even more cases in the future where local compute is needed (e.g. how about the Moon or Mars?!)
Computer historian
In conclusion:
By trade, I'm a software engineer. By spirit, I'm a computer historian. By George, I'm trying to combine the two (just like these three companies).
Footnotes
I'm kinda showing off something neat with this link -- linkable searching using query-params for my Library book list. I'm proud of this lil' quality of life feature for my site. If you're one of those people who like to strip query params from links, by all means do so, but if you want to share a list of the books I've read about Ancient Rome (why would you want to do this if you're not me?), keep 'em in the link.
Watch this show. If you love computers, watch this show. If you love great characters making terrible decisions, watch this show. And then watch it again using this college-course level syllabus by Ashley Blewer.
Notes on My Chemotherapy
Nobody likes an addendum.
Appendices are great (ask any Tolkien fan). P.S.'s are the best (especially if they're from a penpal).
But addendums. Nope. They change the rules, after you've started playing. After the game's over, even.
I recently got dropped with this whopper of an addendum:
Orcein stains performed on blocks A3 and A5 highlight elastic fibers
wrapping around nests of tumor cells, consistent with vascular invasion
A lil' background
Previously, on "Halt and Catch Cancer", I thought I was in the clear. Sure, I'd been diagnosed with Stage II colon cancer at age 34. But the neato robotic surgery to remove my sigmoid colon (and my grisly barnacle of a tumor) was successful, with no signs of the cancer spreading to the nearby lymph nodes (which are essentially the Information Superhighway of your body's immune system).
Officially, we're talking a PT3N0 pathology, where N means the number of lymph nodes with tumor cells (zero, in my case, of the 21 that were removed and inspected) and T means the levels of colon wall that the tumor "broke through." N0 is awesome and T3 is not-so-awesome. My tumor was pretty darn close to breaking through the colon wall. But the fact that I had no lymph nodes affected was a good sign -- a good enough sign that no chemotheraphy was being recommended by my USCF doctor crew.
Now, after my blog post on this whole "cancer sitch," I'd been in touch with friends and other wood-workers who were, unfortunately, familiar with this process. One, in particular, has been highly tuned into the research and literature around colon cancer, and he pushed me to make sure I fully understood my pathology. He also mentioned that he's seen folks with my PT3N0 pathology do chemotherapy on a preventative basis. Given that my big missive in my last post was about "becoming your own health advocate," his advice hit hard, because I was already lapsing in my attentiveness. Frankly, I was exhausted from the surgery, relieved by the results, ready to move on, and the pathology report itself was confusing af.
Actually, you know what? I'm just going to paste it here:
FINAL PATHOLOGIC DIAGNOSIS
Sigmoid colon, sigmoid colectomy:
1. Adenocarcinoma, moderately-differentiated, invasive through
muscularis propria into pericolic adipose tissue, negative margins; see
comment.
2. No tumor in twenty-one lymph nodes (0/21).
COMMENT:
COLON CARCINOMA SYNOPTIC COMMENT
- Procedure: Sigmoid colectomy.
Result Information
All Reviewers List
Pathology PDF Report
Narrative & Impression
Harrington, Charles
- Location of tumor: Sigmoid colon.
- Tumor size: 3.3 x 2.5 x 1 cm.
- Macroscopic tumor perforation: Not identified.
- Histologic Type: Adenocarcinoma.
- Histologic Grade: Moderately-differentiated (low grade).
- Microscopic depth of invasion: Tumor invades through the muscularis
propria into pericolic soft tissue (pT3).
- Margins: Negative.
- Proximal margin: Negative (tumor is > 4 cm from margin).
- Distal margin: Negative (tumor is > 4 cm from margin).
- Circumferential (radial) margin: Negative (tumor is > 3 cm from
margin).
- Treatment effect (modified Ryan score, scale 0-3): No known
presurgical therapy.
- Lymphovascular invasion: Not identified on H&E (orcein stains will
be performed on blocks A3 and A5, and the results will be reported as an
addendum).
- Perineural invasion: None.
- Tumor Deposits: Not identified.
- Lymph node status: Negative (number of lymph nodes examined: 21).
- Other pathologic findings: None identified.
- AJCC Pathologic Stage: pT3N0.
- Ancillary studies: Immunohistochemistry for DNA mismatch repair
proteins will be reported in an addendum.
Addendum Comment
Immunohistochemistry was performed to evaluate the status of DNA
mismatch repair protein expression on block A3. The results in the tumor
cell nuclei are:
MLH1 expression: Present.
PMS2 expression: Present.
MSH2 expression: Present.
MSH6 expression: Present.
Expression for all four markers, in most cases, indicates that the DNA
mismatch repair proteins are intact. This result should be correlated
with the clinical presentation and family history to determine the need
for further work up for Lynch syndrome
Probably TMI, but this will actually be easier for me to find later, instead of spelunking through the oh-so-painful EPIC MyChart software. Am I allowed to share this? I DON'T KNOW AND I DON'T CARE.
As you can see, this plaintext nightmare is full of strange and wonderous medical terms. Yes, the doctors walk you through it but still... it's a lot. I did push them to explain the terms, like what negative margins mean and why they're a good thing, although I kind of forget already so I won't try to explain.
After this walk-through with the docs, I felt good about my plan. No chemo needed. Just ongoing tests and CT scans and blood work and colonoscopies over the next five years to make sure that the cancer wasn't back, led by the UCSF Cancer Survivorship Clinic. Sure, that wasn't nothing, but it also isn't that bad, considering how lucky I am to have caught this thing and gotten it removed ASAP. The idea was, after five years, I'd be back in the general population for risk of colon cancer. Cured.
But then, during my first Survivorship Clinic convo in November, I recalled that one line from the pathology... the one mentioning the addendum that I hadn't yet seen. I ask about it. We dig in, and we find this:
Addendum Comment
Orcein stains performed on blocks A3 and A5 highlight elastic fibers
wrapping around nests of tumor cells, consistent with vascular invasion
Consistent with vascular invasion. Welp, that can't be good.
At this point, I'm immediately whisked off the UCSF Oncology Department.
New faces and new tests and new plans
A hospital is a series of interconnected rings, all slightly Venn Diagramming each other, kind of like the Olympics logo. As a patient, you tend to orbit one of the rings. But sometimes you'll Three Body Problem your way over to another ring.
In my entire diagnosis and surgery process, I'd never made it over to the Oncology (aka cancer) ring -- I was stuck in Surgery World. But, after this addendum, I'm now squarely in their circle.
So, what's our goal now? Well, now that we've noticed that my cancer has slightly spread into the vascular system, we need to figure out what to do about it. First, let's remember the good stuff - the rest of the pathology is relatively awesome. Next, let's get some more data!
We do these tests:
- Signatera - looks in your blood for tumor cells
- Oncotype - looks at your tumor and rates the likelihood of recurrence
Let me reiterate that my explanations of these tests (and anything medical-related) is entirely my random-dudeman-laymen's explanation. I hope to provide one person's context and interpretation of these confusing and scary things. I'm open to feedback and information on what I can do better.
Insurance aside
Insurance didn't want to cover the Oncotype test, because, of course. Insurance doesn't want to cover a lot of things, especially brand new "cutting edge" stuff, like the Oncotype test.
Instead, insurance wants to make sure that you really-super-duper-need whatever it is they're going to give you, to the point where there's basically no way they can say no. My doctors have been amazing advocates for me, helping make sure that insurance knows how important these tests and treatments are for my health. THANK YOU, UCSF.
Insurance is frustrating and scary. I do not understand it. I do not want to understand it. I wish it was simpler. I wish I didn't have to make sure that I was "covered" for things related to my health and my family's health. I also know that I'm incredibly lucky to have good insurance. I took a screenshot from my insurance app back in December:
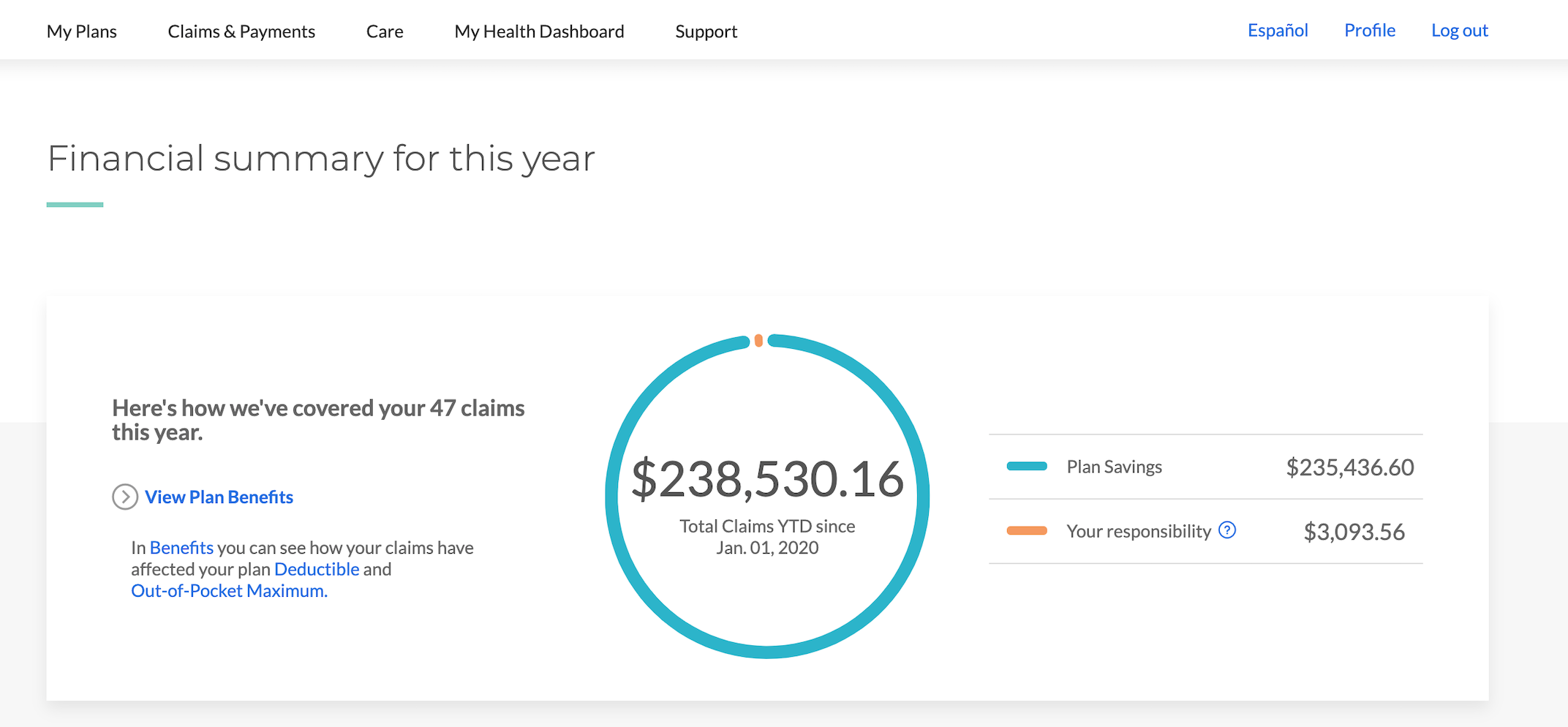
WTF. That's an insane amount of money. But my life was saved, sooo...? The insurance company even assigned me a nurse to "check in on me" as a resource back in November and December, which sadly was more of a nuisance than anything else. And, then, when my company switched insurance providers at the beginning of 2021, this nurse service stopped abruptly. The whole thing's odd. But I can say again that I am extremely grateful to have had good insurance during my cancer treatment.
Make a new plan
The Signatera is clear, which is great. No circulating tumor cells in my blood. I ask the question, "Doesn't this mean I'm, like, good for life now?" And apparently no. They can't say that. They can only say, "We don't see anything right now." It's the balance sheet of cancer. Just cause things look good right now doesn't mean that next year or next quarter's gonna be the same. Past performance is no indication of future something-something.
Oncotype's pretty good, too. From what the doc explains, this test suggests that my tumor has a 12% recurrence rate. This is a low number and I should be happy about it. And I am. But I want it to be zero, obviously. Also, recurrence isn't talking about new polyps growing in my butt and starting cancers -- that can still happen. Recurrence is about whether cells from my now-removed cancer tumor are going rear their awful heads again, somewhere else in my body.
It's at this point that we get into the discussion around chemo. There's evidence that chemo can help reduce the recurrence rate even further. My oncology team brings my data to this cool-sounding UCSF "Tumor Board" meeting, and they advise a chemo treatment. The evidence suggests that we can bring down my recurrance rate from 12% to 6%.
But they also reiterate that it's my choice. I can say no. As my aforementioned friend said, "You don't do chemo recreationally." In fact, the doctors explain that if I were an old man, they might not advise treatment. But since I'm young and restless, it makes more sense for me to do whatever I can to improve my chances.
Duh, let's do this thing.
So, what's chemotherapy like?
Well, first of all, there's all different kinds of chemo. I didn't know that. I'm on a combo colloquially called CAPEOX (which I thought sounded a bit like a rival Star Fox gang). It stands for capecitabine (brand name is Xeloda) and oxaliplatin. Cape comes in pills and ox is an IV drip.
But wait -- more decisions. Do we do six months or three months of treatment? We review the data from a Japanese study, and we conclude that there's no measurable difference, so we go with 3 months, due to risk of chemo side effects.
Chemo is not a pure function
Chemo has side effects. Here are the things that I've encountered so far:
- super cold fingers and toes
- lockjaw when I start eating
- clenching claw hands
- it hurts to cry (and I just finished the last season of Halt and Catch Fire, so yeah..)
- no appetite, not even for pizza or beer
- nausea
- kinda a sad feeling
- dead sperm(!)
Shockingly, there's no hair loss expected. I'm already in a thinning situation "up there," but it's not supposed to get any worse. A small, dumb part of me thinks that once treatment's over that it might even get better! But this small part is very dumb.
Let's talk about the sperm stuff. As a result of doing chemo, there's a good chance that my swimmers are gonna be dead for good. There's also a chance that they can come back. But, if I want to ensure that Carly and I can have the family we want, I need to do sperm banking, quickly! Apparently, there's a ticking clock on starting chemo post-surgery (something like within 8 weeks). So, I've got a week to do as much sperm banking as I can! Fun!
The sperm banking process is hilarious. You go to a building, then into a waiting room, then you are led to a tiny little room with a metal door in the wall. When you are done collecting your sample in a cup, you open the door in the wall and put the cup in there, and then press a button, and someone on the other side grabs it. In between that, there's literally a Roku porn subscription and a big TV. I went four times in a week. We got some good stuff collected.
Another note on the 3 months vs 6 months decision - there are other potential side effects to chemo that factor into the timing decision. The big one in my case is something called neuropathy. Essentially, chemo can potentially cause long-term, life-altering nerve damage. The signs of it often begin with numb feet and hands, which I will admit seem rather easy to confuse with the expected, but not serious symptoms of cold hands and feet. The docs explain that any signs of neuropathy need to be reported immediately and we will halt chemo immediately, because the long-term negative effect of neuropathy far outweighs the gains in any reduction of recurrence rates in my case.
Now, given of all that prep and preamble, it's finally time to start chemo!
Charlie the Cyborg
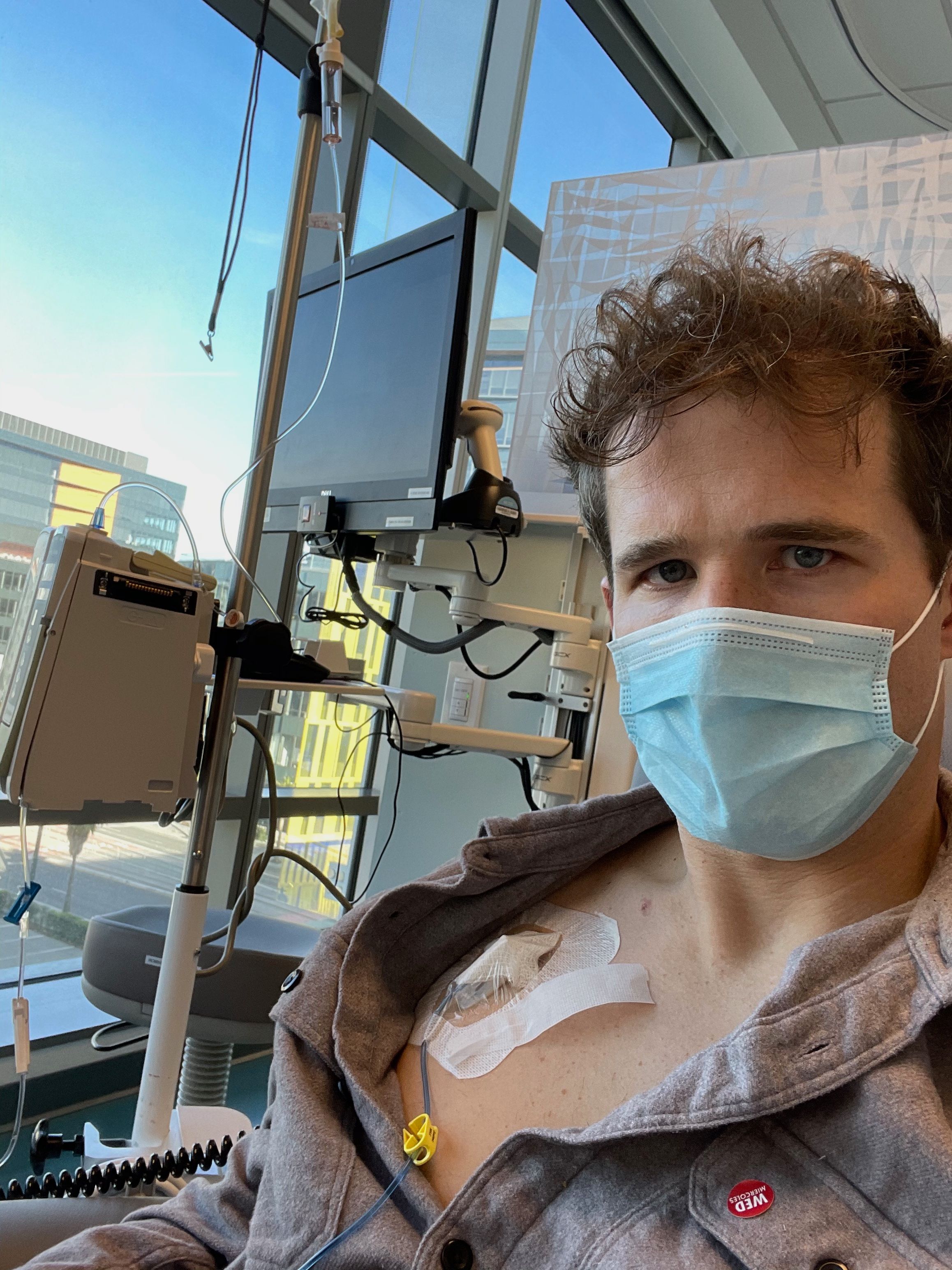
Wait. We need a way to get the chemo into your body. There's two options: a PICC line or a port. In either case, we need a tube that's threaded through your veins directly above your heart. If you go PICC, we gotta thread that in for every single treatment. If you go port, you only do that once, but you get this Tony Stark metal disk thing in your chest. You can guess which one I chose.
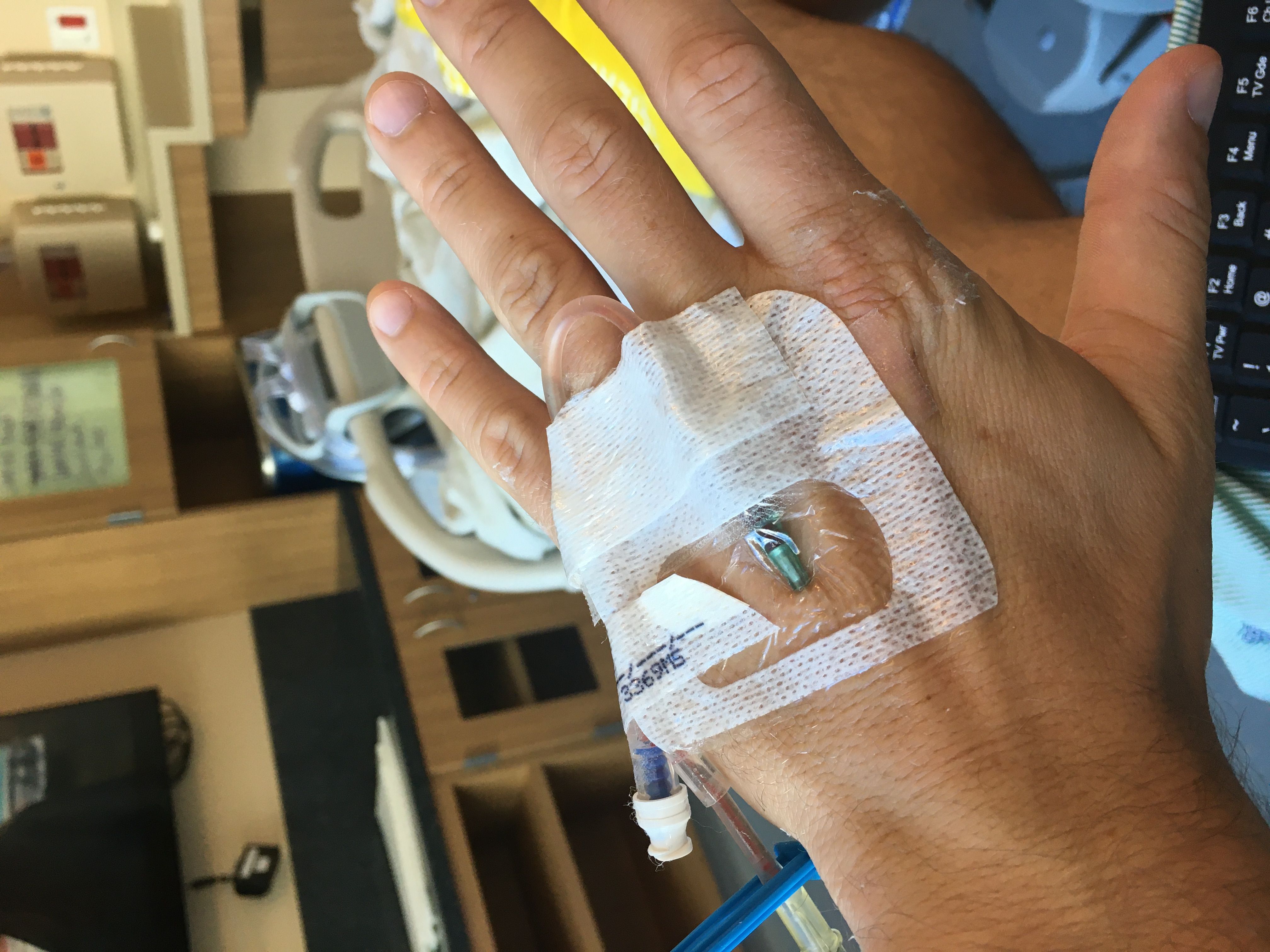
Now I have an ID card that explains why metal detectors don't like me anymore.
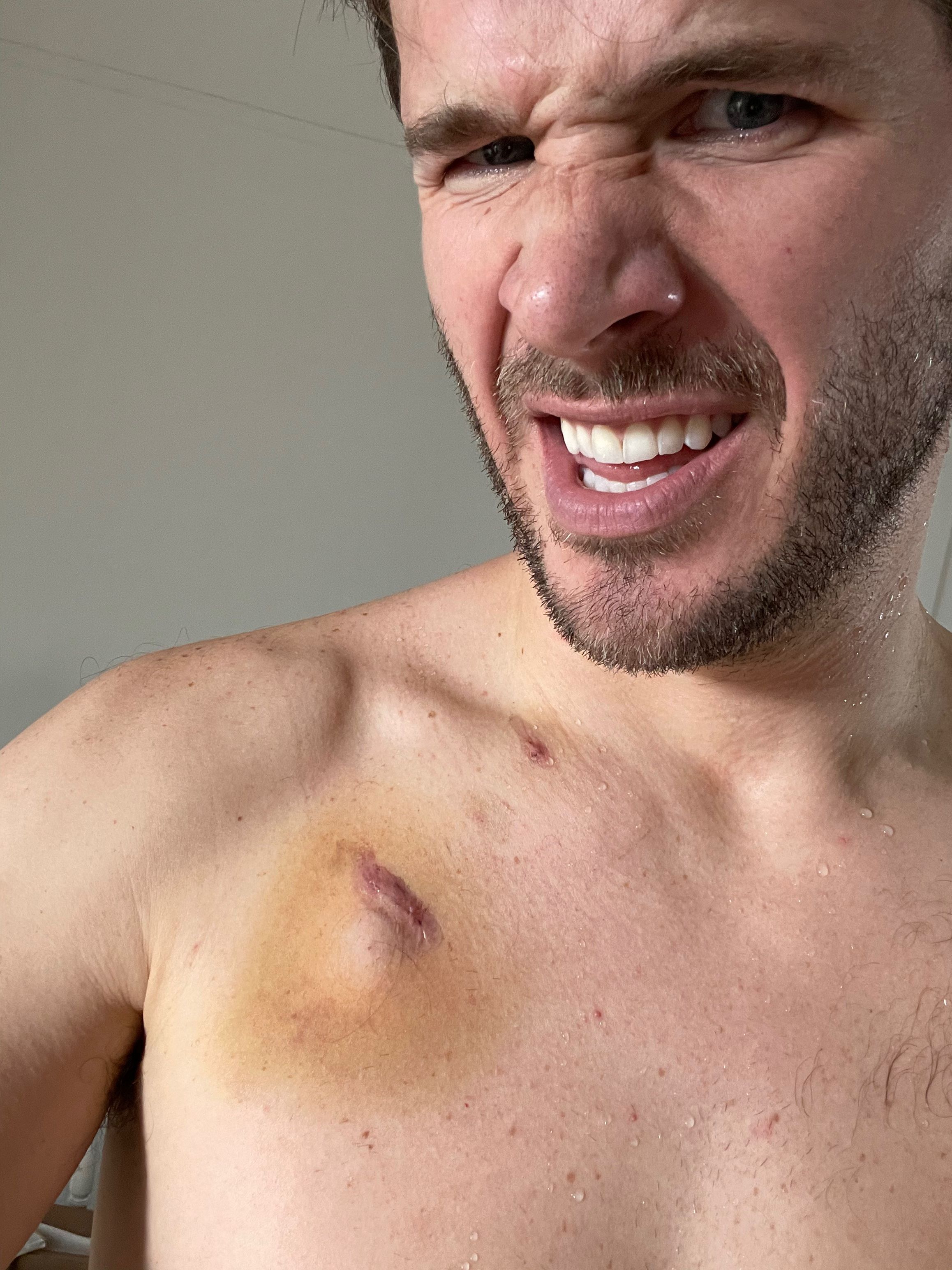
Gross and weird, but also cool and weird. With this port, it's a simple little pin prick to get me all connected to the IV stuff. Here I am plugged in.
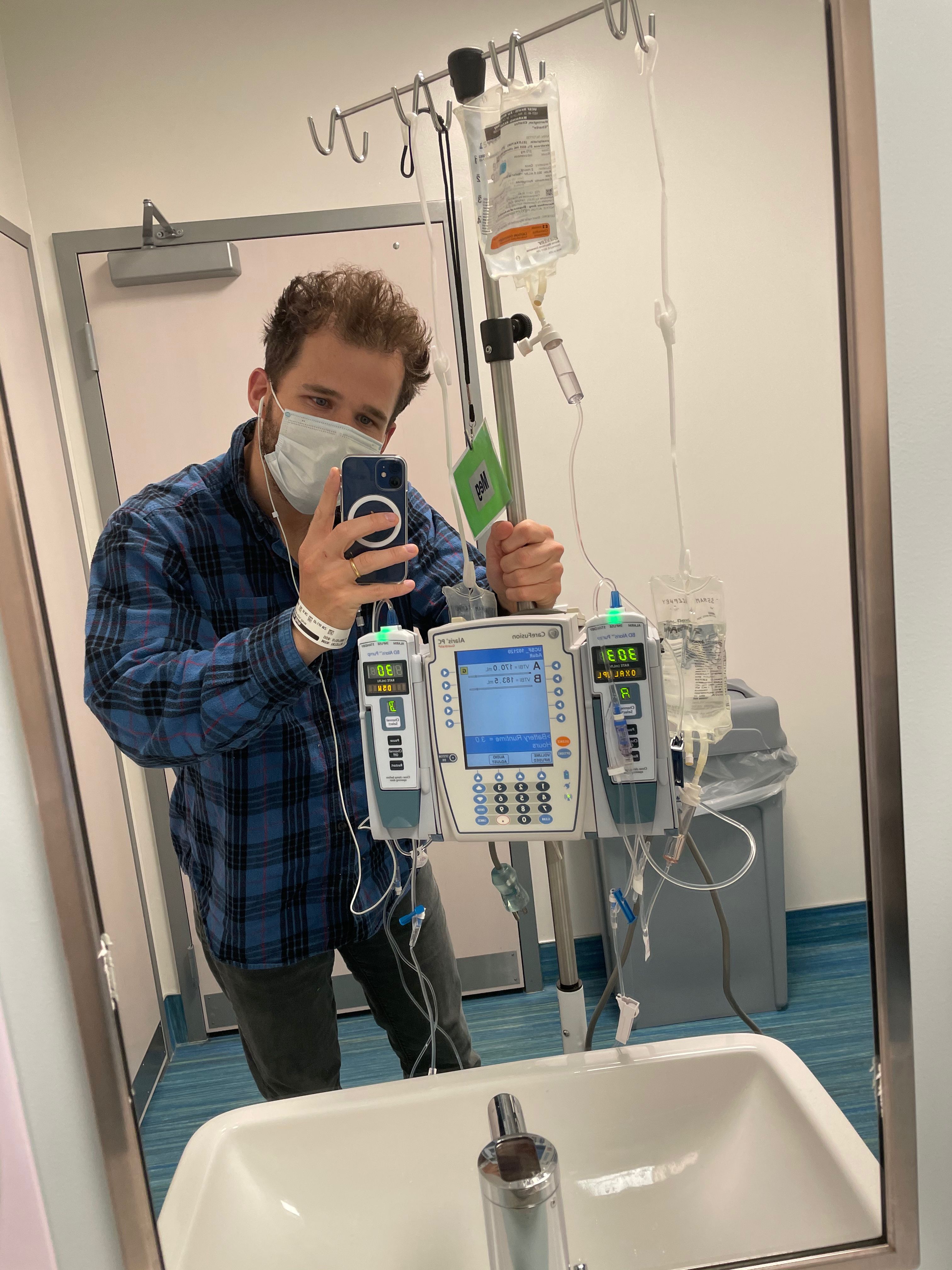
My three week cycle consists of this:
- Day One: Ox drip and start taking pills
- Next 2 weeks: pills 2x a day
- Third week: Nothing
Then, start over, for 4 times total.
The point of the third week is to help your white blood cells recover. The chemo fries them, too. It basically kills anything fast growing in your body (my interpretation!), so your useful blood cells (and sperm and hair etc etc) are impacted. Not a super great thing to happen during a global pandemic, weakening your immune system and all.
The drip takes like 2 hours. I usually bring some books and a chicken parm sub and my Nintendo Switch. Here's me after a pee-break:
I buy this pill box on Amazon, cause why not:

This sucker lives in our kitchen counter in plain sight so that I never forget to take my 2x a day sets, and so far, I haven't ever forgotten.
What next?
This has been a long, strange trip of a six-month period. I'm currently in the second week of the third cycle. My third cycle had to be pushed back a week because my white blood cells were too low. I came back the next week, and they were still low, but we decided to proceed, and just dropped my cape dosage from 2000mg to 1500mg (3 pills 2x a day instead of 4 pills 2x a day). In another week, I get to have the glorious "week off" (when I again crave the taste of beer), and then we're back for the fourth and final round.
I can't wait for this to be over. I can't wait for this port to be out of my chest. I'm happy that I'm doing everything I can to ensure that I have a long and healthy life. I'm eager to get back on the UCSF Survivorship Clinic plan, and start improving my diet to reduce inflammation (and all this other stuff that's supposed to help prevent cancer).
I have learned a lot about cancer and health. My heart breaks when I think about children who've suffered from cancer. My infusion center is the adult center. I'm not sure I could stomach seeing children and babies getting chemo. I'm crying right now even thinking about it (which hurts, if you remember my side effects). Cancer is terrible and it can affect anyone. This is where I re-impart my advice about being your own health advocate.
Thanks to Carly and my family and friends and work peeps for your love and support.
Fuck cancer. Create wonderful things, be good, and have fun.
Making podcasts from Project Gutenberg e-books
I recently watched Pixar's SOUL and I loved its depiction of being in the zone:

This is a beautiful, astrally-projected depiction of Mihaly Csikszentmihalyi's flow concept. For the unfamiliar, here's how Csikszentmihalyi describes flow, or the optimal experience:
It is what the sailor holding a tight course feels when the wind whips through her hair, when the boat lunges through the waves like a colt -- sails, hull, wind, and sea humming a harmony that vibrates in the sailor's veins. It is what a painter feels when the colors on the canvas begin to set up a magnetic tension with each other, and a new thing, a living form, takes shape in front of the astonished creator.
That sounds pretty good, right? Csikszentmihalyi contends that flow is how we humans can achieve happiness. And it's not something that's given; it's something we have to cultivate and grow and work towards. I cannot recommend his book enough.
Even better was SOUL's depiction of the non-flow state - the lost souls:

Definitely been there. Usually its whenever I hear, "Can you see my screen?" These poor creatures wander the astral plane, lost and unhappy and unsure why.
Luckily, the movie tells us it's never too late, and I believe them.
So, how do we achieve flow?
It's the deliberate combination of skill meeting challenge. More from Csikszentmihalyi:
The best moments usually occur when a person's body or mind is stretched to its limits in a voluntary effort accomplish something difficult and worthwhile.
This post documents a legitimate flow experience I had last week that began with an observation about my podcast addiction.
All My Best Friends are Podcasts
Yes, that's a Less Than Jake reference. You're welcome, 8th-Grade Charlie.
And, if you're at all like 28th-Grade Charlie, then you're also helplessly addicted to podcasts.
I listen all the time -- while I'm washing dishes, folding laundry, performing my daily Amazon cardboard box cutting ritual, even taking showers. Carly doesn't understand it, and I certainly can't explain it.
Am I that afraid of silence? My own thoughts? Am I so lonely for friendship that I even found this evisceration quietly comforting?
Podcasts saying literally nothing for 20 minutes. pic.twitter.com/nmfka1Gjsp
— Jonathan Ogden (@jogdenUK) January 5, 2021
I know too much about ancient Rome to be able to answer these questions.
So, if I'm just going to accept my Overcast overlords, can I turn the tides on this one-directional relationship?
Yes. We can. Enter: the spark of an idea.
Create a podcast from the audio of YouTube videos
If I can't control what my favorite podcast hosts are talking about in any given episode, can I instead choose exactly what I want to listen to? What if there were a virtually unlimited source of content to consume? Surely, I could then be more deliberate in my listening habits.
YouTube is our answer. I've been collecting computer science talks and lectures in playlists that I always mean to "watch later" and never do. Fact is, I don't want to watch a YouTube video. I rarely ever sit down and "watch YouTube" (other than The 8-Bit Guy cleaning old VIC-20s). It's not part of my routine. I'm usually moving around too much.
YouTube also makes it really hard to consume something "on the go." You need to pay for their PiP or minimized mode, I think.
Then I found this post by Benjamin Congdon: a simple way to create an audio podcast feed from a YouTube playlist using a Raspberry Pi home server. His tutorial leverages an open source project called PodSync, which itself leverages ffmpeg and, everyone's favorite controversy, youtube-dl, behind the scenes to download audio from YouTube and generate a podcast RSS feed. This, this, is exactly what I was looking for!
Nothing to add here, other than bravo, Benjamin. I was able to follow his tutorial pretty much straight through.
Wait, I do have something to add. Benjamin suggests using rsync to upload your mp3s and xml RSS feed to s3 or the like. I did this initially, but I didn't like the idea of having to mark these files as public on s3 in case of some huge accidental traffic surge.
So I came up with another idea:
- Create a public repo on GitHub and enable GitHub Pages (mine is here)
- Init the repo in your
/datadirectory on the Raspberry Pi (this is the directory with the generated.xmlRSS feed andmp3audio files) - Change your Podsync config's hostname to your GitHub Pages site:
hostname = "https://rockswhat.github.io/listener"`
- Change your cron command to push to your repo (instead of
rsyncto s3):
*/15 * * * * cd /home/pi/podsync/data && git add . && git commit -m "update feed" && git push origin main
Voila! My own podcast feed of YouTube videos, publicly available on the Internet. You can add my feed to Overcast (or your favorite podcast player) with its XML URL:
https://rockswhat.github.io/listener/listen_laterz.xml
C'mon, you really achieved flow from that?
No, not really, but almost. Tutorials, good ones, at least, are guided paths toward some goal, with micro-feedback and mini-frustrations along the way. And these things are well-suited to flow. They can lead you to flow.
In my case, this tutorial got my gears turning. Which now gets us into to the creative computing side of this article.
I think it's important to remind ourselves to have fun with our computers. To use them to make art, make music, create weird stuff, just because we can. There's so much on our computers and phones now thanks to the Internet that can warp our minds and render us into Lost Souls. We often forget the simple joys of computers of the past, back when they were bicycles for the mind, and used adorable floppy disks or CD-ROM drives for games and encyclopedias. I know there's so much "more" that we can do with computers, but we need to remember that they are here to work for us, and not the other way around.
As soon as I saw Overcast fill up with audio from my Listen Laterz YouTube playlist, I knew I needed to keep going, to see what else I could render from clay into podcast feeds.
Creating a podcast audiobook from Project Gutenberg e-books
Where else can we find a giant repository of open content on the Internet that also happens to be inconvenient to consume?
Hello, Project Gutenberg!
Project Gutenberg is just about the coolest --- and one of the most important -- things on the internet. The fact that it was started on the ARPANET in 1971 blows my mind. That is some creative, forward-thinking from its founder Michael S. Hart.
My idea here is simple: pick a public domain book, chop it up into chapters, convert the chapters to audio, and then generate an xml RSS feed.
I picked Mary Shelley's Frankenstein, because, why not? I already read it a few years ago during my October "Spooky Reads" habit, but I figured it's the perfect candidate for re-animation.
If you've clicked the link to the text on Project Gutenberg, you'll see it's a plaintext nightmare. I'm not ashamed to admit here that I manually just chopped it up into separate text files, rather than writing a script to somehow do this for me. Whatever, ok?
First let's make some files.
cd pieces
touch intro.txt
touch letter-{1..4}.txt
touch chapter-{1..24}.txt
touch license.txt
And then we copy-pasta.
Now that I've got my chapters (aka future podcast episodes) all set, we're ready to convert them to audio. What's the easiest way I can do that?
My "in-the-zone" brain suggests using the terminal's say command. I've used this command a few years ago in one of my earliest creative computing projects: a live musical performance from a telepresence robot).
Surely, I can write a neat little script to loop through my text files and say them into an mp3. Some Googling for advice, and I've soon got this Bash script going:
for i in *.txt;
do
echo "processing $i...";
name=$(echo "$i" | cut -f 1 -d '.')
say -v Vicki -f $i -o aiff/$name.aiff
lame -m m aiff/$name.aiff mp3/$name.mp3
rm aiff/$name.aiff
done
And it works! Checkpoint reached! The mp3 files are now sitting happily in their respective /mp3 folder. I experience a fleeting moment of joy, and then immediately plunge into the next challenge: generating an XML feed.
My hack-y brain suggests another copy-pasta. Let's take the feed generated by the Podsync library in the section above, replace pieces of it with Bash variables, and then loop through my text files to jam in the values I want.
More googling ensures, including learning a bit more about heredocs, and I've eventually got this script:
#!/bin/bash
# edit these to your liking
PODCAST_TITLE="Castellan - Frankenstein"
PODCAST_AUTHOR="Castellan"
CATEGORY="Technology"
GENERATOR="Castellan"
LINK="https://whatrocks.github.io/castellan/"
IMG="https://whatrocks.github.io/castellan/showart.jpg"
# automatic
CURRENT_DATE=$(date -R)
# order
EPS=(
intro
letter-1
letter-2
letter-3
letter-4
chapter-1
chapter-2
chapter-4
chapter-3
chapter-5
chapter-6
chapter-7
chapter-8
chapter-9
chapter-10
chapter-11
chapter-12
chapter-13
chapter-14
chapter-15
chapter-16
chapter-17
chapter-18
chapter-19
chapter-20
chapter-21
chapter-22
chapter-23
chapter-24
license
)
read -d '' feed << EOF
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd">
<channel>
<title>$PODCAST_TITLE</title>
<link>$LINK</link>
<description>$PODCAST_TITLE ($CURRENT_DATE)</description>
<category>$CATEGORY</category>
<generator>$GENERATOR</generator>
<language>en-us</language>
<lastBuildDate>$CURRENT_DATE</lastBuildDate>
<pubDate>$CURRENT_DATE</pubDate>
<itunes:author>$PODCAST_AUTHOR</itunes:author>
<itunes:subtitle>$PODCAST_TITLE</itunes:subtitle>
<itunes:summary><![CDATA[$PODCAST_TITLE ($CURRENT_DATE)]]></itunes:summary>
<itunes:image href="$IMG"/>
<itunes:explicit>no</itunes:explicit>
<itunes:category text="$CATEGORY"></itunes:category>
EOF
echo $feed
COUNT=1
for episode in ${EPS[@]}; do
echo "processing $episode..."
MP3_FILE="book/pieces/mp3/$episode.mp3"
MP3_SIZE="$(wc -c <"$MP3_FILE")"
UUID=$(uuidgen)
NEXT_DATE=$(date -R)
DURATION="$(ffprobe -show_entries stream=duration -of compact=p=0:nk=1 -v fatal $MP3_FILE)"
read -d '' next << EOF
<item>
<guid>$UUID</guid>
<title>$episode</title>
<link>$LINK$MP3_FILE</link>
<description>$PODCAST_TITLE: $episode</description>
<pubDate>$NEXT_DATE</pubDate>
<enclosure url="$LINK$MP3_FILE" length="$MP3_SIZE" type="audio/mpeg"></enclosure>
<itunes:author>$PODCAST_AUTHOR</itunes:author>
<itunes:subtitle>$episode</itunes:subtitle>
<itunes:summary>Audio generated from the text of this chapter</itunes:summary>
<itunes:image href="$IMG"></itunes:image>
<itunes:duration>$DURATION</itunes:duration>
<itunes:explicit>no</itunes:explicit>
<itunes:order>$COUNT</itunes:order>
</item>
EOF
feed="${feed}${next}"
COUNT=$((COUNT+1))
sleep 5
done
END="</channel></rss>"
echo $feed$END | tee podcast.xml
Lots of minor bugs and typos later, and I've got my RSS feed! Is this script hideous? Sure, but it works! I'm having fun and that's all that matters right now. Speaking of fun, I also had to create cover-art, obviously:

Finally, using the same GitHub Pages approach, I upload my stuff and import my Franken-pod into Overcast, like so:
I decide to call the project Castellan because it has the word "cast" in it and it means keeper of a castle or something, and that feels pretty Frankenstein-y to me.
Finally, I give it a listen...
And it's a horrible monster. Here, I dare you to listen:
We've gotta do something about this, cause this thing doesn't sound human at all.
Machine learning to the rescue?
For a brief moment, I escape my zen-like programming mindset, and I go to the orange website and encounter a post about a new text-to-speech deep learning project, and it's damn good. Unfortunately, it's not open source.
Surely, there's a good open source text-to-speech project out there. Some more googling, and there is! I find the tts project from Mozilla, which deliciously provides a few Google Colab notebooks (aka Jupyter Notebook / Jupyter Lab) with pretrained models ready to go!
This is great news. Instead of the say command, I'm going to pump my chapters into this trained model and it's going to be awesome.
Except the models clip out after three sentences or so. I do some spelunking, and the model is meant to go sentence by sentence, rather than huge swaths of text at once.
But that's no problem for me.
I'll just split on the . period character, generate the audio once sentence at a time, and then concat them all together at the end.
Here's a link to my Colab notebook that you can try yourself. The only things I changed in this notebook are the bottom four or so cells.
Here's how I make my machine learning powered audiobook podcast:
Mount my Google Drive, where I've dropped the text files (and I'll store the generated mp3s):
from google.colab import drive drive.mount('/content/gdrive', force_remount=True)Install the
pydublibrary to handle audio files!pip install pydubRead my text files of the chapters from Google Drive into an array of tuples for processing
import os path = '/content/gdrive/My Drive/Castellan/' chapter_path = f'{path}pieces' chapters = [] for file in os.listdir(chapter_path): if file[-4:] == ".txt": with open(f'{path}pieces/{file}', 'r') as chapter: chapter_text = chapter.read() name = file[:-4] chapters.append((name,chapter_text))Loop through the array, split each chapter into sentences, skip weird textual issues like newlines and other nonsense, run each sentence through the
ttsmodel, concat/reduce that sentence with a accumulating wav file of the entire chapter, and then save the accumulated wav file to an mp3 in Google Drive. Phew! That's a mouthful:
import scipy.io.wavfile
import uuid
from pydub import AudioSegment,s
silence = AudioSegment.silent(duration=500)
for chapter in chapters:
print(f'processing chapter {chapter[0]}...')
chapter_audio = silence
for sentence in chapter[1].split('.'):
# skip these
if sentence == '”\n' or sentence == '\n' or sentence == '\n\n':
continue
sentence = sentence.strip('')
# more skips
if len(sentence) == 0 or sentence == '':
continue
# generate wav
align, spec, stop_tokens, wav = tts(model, sentence, TTS_CONFIG, ap)
# save wav file
wav_unique = str(uuid.uuid4())
wav_name = f'{wav_unique}.wav'
wav_path = f'{path}wav/{wav_name}'
scipy.io.wavfile.write(wav_path, TTS_CONFIG.audio['sample_rate'], wav)
# read wav file
sound = AudioSegment.from_file(wav_path, format="wav")
# combine it
chapter_audio += sound
chapter_audio += silence
# save mp3 file
file_handle = chapter_audio.export(f"{path}mp3/{chapter[0]}.mp3", format="mp3")
print(f'done with {chapter[0]}!')
As you might have guessed, the above cell is the end result of much experimentation. Jupyter Notebooks make this iterative development insanely easy, and I only was able to pull things together like this after I'd figured out each individual piece. Jupyter Notebooks are like REPLs + documentation in one.
Once I had this all set up, I hit run all cells and went to sleep. When I woke up, I discovered that about half of my chapters had successfully processed! The only reason it didn't chug through all of them was the Google can randomly preempt your machine at any time, or they have a 12 hour timeout for CPUs. This felt a bit like it must have felt when you feed all your punchcards into the IBM mainframe, and there was some bug halfway through your stack.
No worries, I just removed the already processed chapters from my text files, and re-ran it. I can deal with this annoyance, because this is a toy project. And it's free. And my laptop fan is silent, almost like it's a brand new M1 Macbook, because I'm running this on Google machines.
Want to hear the result?
Dang!! That's so much better. Sure, it's still a little weird. But it's actually listen-able now. Thank you, machine learning!
I moved these files from Google Drive onto my local, and then I re-ran my XML generator script, changing the title to "Frankenstein Jr" and referencing the new better mp3s, and then pushed to Github Pages.
Here's a link to the podcast feed that you can add to your own player.
Sure, there's still problems. I've encountered these occasional weird sections where the tts voice just completely glitches out, perhaps due to the weird encoding of Project Gutenberg files (could be a \t character or something). I know that much of machine learning is about "cleaning up your data," so I could probably spend more time doing that, but Frankenstein-ly, I've already flowed onto my next idea.
Parse a screenplay and create voices for each character
Wouldn't it be amazing if you could recognize the characters and give them each a unique voice? That's gonna be hard with novels, but you know what's much easier: screenplays! They've got the characters broken out into discrete, named sections, like this:
PRINCESS
I love you.
SMUGGLER
I know.
The smuggler is lowered into the machine. HISSES and SQUEALS. Everyone, including THE BIG BOSS, turns away.
I just made this scene up ^, okay?
I could parse a screenplay, then pass each character's lines into a model with a specific voice.
Oh! I know there's sentiment analysis models. What if I first feed the sentences into a sentiment analysis model, and then feed that sentiment into the text-to-speech model.
Now, we're talking...
You can see where this is going. My brain is reeling with possibilities and new directions and new ideas.
This is creative computing. This is why I love programming and its ability to get you into the flow state.
I haven't tackled the screenplay parsing bit yet, but maybe I will. I'm just grateful that I was able to have fun with this project. This is how I want to live my life, being creative, having fun. This is how Csikszentmihalyi describes a life with flow:
Such individuals lead vigorous lives, are open to a variety of experiences, keep on learning until the day they die, and have strong ties and commitments to other people and to the environment in which they live. They enjoy whatever they do, even if tedious or difficult; they are hardly ever bored, and they can take in stride anything that comes their way.
I couldn't have put it better myself, obviously. John Cassidy of Klutz Press, my favorite publisher, does a great job rephrasing this sentiment, though:
Create wonderful things, be good, and have fun.
P.S. Don't you know about LibriVox, dude?
Yeah, so there's already a project called LibriVox that creates audiobooks from public domain texts using real human being voice volunteers. They even provide RSS feeds that you can use in your podcast player. Did I know about this before I went down this rabbit-hole. No! Would it have changed anything no! Maybe? It could have prevented me from exploring ML for this project, and that would have been a bummer.
My takeaway is that your ideas are probably not unique, but that doesn't mean you should explore them and find your own path forward. That's the path to creativity and fun.
Okay, enjoy the feeds!